Balacoon TTS as a service
In recent years, text-to-speech technology has made tremendous strides, thanks in large part to advances in machine learning and artificial intelligence. As a result, synthetic speech is now almost indistinguishable from human speech, and is being used in a variety of applications, from voice assistants to audiobooks.
However, while there are many cloud-based text-to-speech services available, (AWS Polly, Azure Text-to-speech, Google cloud Text-to-speech to name a few) these services can be expensive, and may not always be the best fit for every use case. That’s why we’re excited to announce the release of our new self-hosted text-to-speech service, which is available as a Docker image that you can spin up on a GPU instance.
With our self-hosted text-to-speech service, you can get state-of-the-art speech synthesis within your own infrastructure, without having to rely on cloud service providers. This can be especially useful for practitioners who need to power their app or service with synthetic speech in production, and who may have concerns about cost or security.
As the rest of the post delves into the internal workings of the service, we recommend taking a moment to review the usage documentation, which demonstrates how straightforward it is to establish a TTS endpoint.
How far 1 GPU can take you
This section aims to set expectations regarding the efficiency of Balacoon TTS, specifically in terms of how many users can be served using just one GPU to handle requests. Two primary metrics to consider are:
- Latency - the amount of time a user must wait before obtaining the first chunk of audio.
- Real-time factor (RTF) - the ratio of the duration of the synthesized audio to the time it took to produce it.
Configuring the endpoint involves finding a balance between these two metrics. Balacoon TTS server uses NVIDIA Triton Server internally, which enables batching of inference requests. The greater the number of requests that are batched and processed in parallel, the better the real-time factor will be. However, this comes at the cost of increased latency since processing more data in parallel requires more time. You have control over the maximum batch size to process, when you are launching the endpoint.
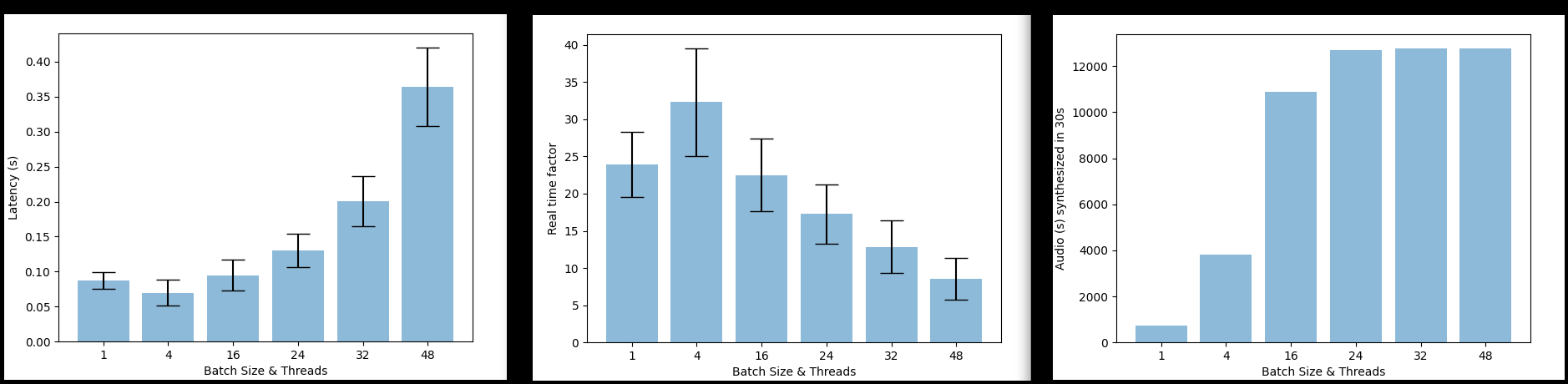
It can be observed that beyond a certain point, increasing the batch size does not result in any significant increase in the amount of audio produced. In total, it is possible to generate 3.5 hours of speech in just 30 seconds, with each user starting to receive audio in as little as 100 milliseconds after the request. Check out the performance of classical combination of Tacotron2 and Waveglow for comparison.
There are other parameters that affect Latency/RTF, but these are hardcoded into the server and cannot be adjusted:
- Chunk size - the amount of audio synthesized in a single processing unit. It is more efficient to synthesize larger chunks of audio, but this can increase latency. The chunk size for Balacoon TTS is set at 2 seconds.
- Batching queue delay - the time to wait for the new requests before sending previously obtained ones as a batch. Balacoon TTS aggregates requests for 10ms.