Balacoon TTS version 0.1.0
We’re excited to announce the release of Balacoon TTS 0.1.0, the latest version of our text-to-speech package. This new version includes two major updates that will significantly enhance its functionality.
- We switch to the use of ONNX as the neural backend. It allowed us to drop the torch libraries and reduce the package size by a factor of 3, making it much more lightweight and easy to use. Using ONNX also provided a 1.4x speedup in synthesis speed
- We add streaming synthesis API for low latency applications. While streaming synthesis is generally 2x slower due to redundant computations, it allows for audio to be sent back to the user immediately after the first chunk is produced, making it ideal for real-time applications. You can find the usage example in the docs.
One caveat is that the updates required us to retrain the TTS models. So you will need to update both package and addons.
ONNX Runtime
ONNX Runtime is a powerful open-source engine that provides a universal neural backend for deploying and optimizing deep learning models trained with different frameworks. It simplifies the release of a library to different platforms (Windows, RaspberryPi, Android are in the roadmap) and allows for different optimizations. Additionally, it enables the export of models to even faster backends such as TensorRT, which we will explore in the future. At present, we plan to use ONNX as a backend for CPU inference, although there are still some unresolved issues to address, such as half-precision inference on CPU.
Streaming synthesis
Streaming speech synthesis is an important technology that enables real-time generation of speech while reducing perceived latency[1]. This approach to speech synthesis breaks down the process of speech generation into smaller chunks, allowing the system to produce and deliver audio output in near real-time. This is particularly important for applications where low latency is critical, such as voice assistants, interactive voice response (IVR) systems, and chatbots. While streaming speech synthesis offers a faster response time, it comes at the cost of overall inference speed, as the system is constantly generating small audio segments in real-time. Despite this, streaming synthesis remains essential for applications where real-time audio feedback is necessary.
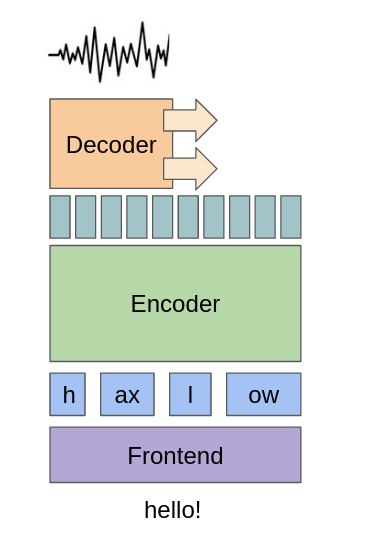
The picture above illustrates the operating principle of streaming synthesis. The process begins with a frontend that takes in textual input and sends it to an encoder, which processes the input at the phoneme level. The encoder then upsamples the phonemes to create frame-level representations. A decoder then slides across these frame-level representations, converting them into audio output one small chunk at a time. By breaking down the speech synthesis process into smaller pieces, the system can produce and deliver speech output in real-time, reducing latency and enabling applications that require fast response times.
References
[1] High Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency. arxiv