Dissecting BARK
Things started to get stale after the ubiquitous switch to Neural Text-to-Speech. A long-awaited leap forward was introduced thanks to ideas from the blossoming image generation field. TorToiSe adopted techniques introduced in DALL-E[1] and simultaneously pushed frontiers of:
- expressive speech synthesis
- paralinguistic generation
- voice cloning
These improvements became possible due to more powerful generative models and an unprecedented training scale. Instead of traditional 20 hours of speech and 10-50M parameters models, TorToiSe used thousands of hours and hundreds of millions of trainable parameters. It sparked a whole series of papers that developed the approach further, with AudioLM[2], VALL-E[3], and SPEAR-TTS[4] being the most prominent among others. In this post, we will explore the internals of the BARK - an open-source implementation of this new speech synthesis paradigm.
Architecture
BARK quite closely follows VALL-E architecture, utilizing a large autoregressive transformer decoder to operate on discrete speech representations.
Tokenization
Discrete speech representations or tokens are obtained from two pre-trained models - HuBERT[5] and Encodec[6]:
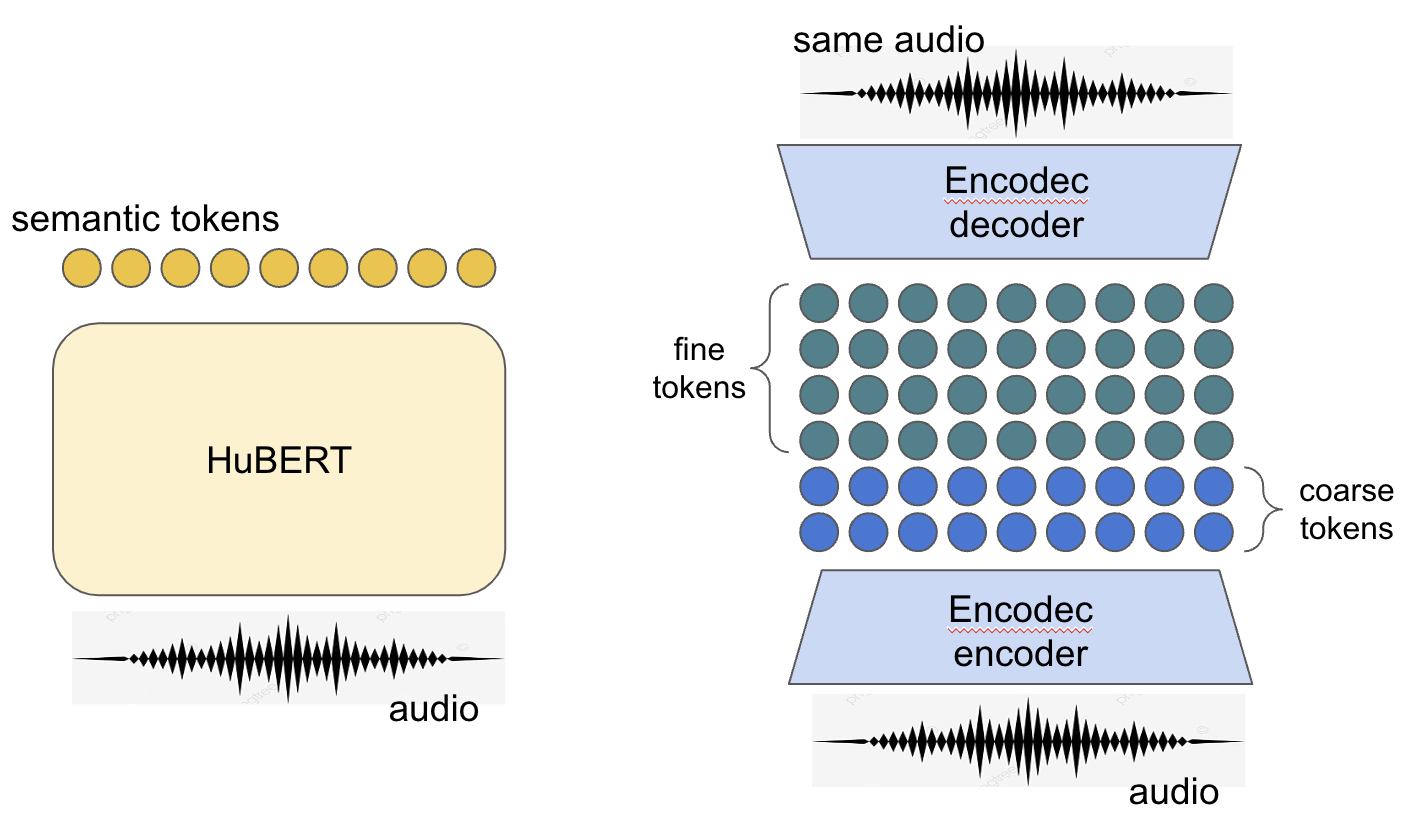
HuBERT is a semi-supervised model that converts audio to discrete “semantic tokens.” The objective of the HuBERT training makes extracted representations speaker- and prosody-(quasi)independent. Think of pseudo-phonemes annotation on a frame level.
Encodec is a neural vocoder that works on multi-level discrete representations extracted from audio in an auto-encoding manner using vector quantization. Think of mel-spectrogram frames but discrete. Low-order representations are called “coarse tokens,” and higher-order ones are “fine tokens.”
Acoustic Modeling
By discretizing the speech into tokens, we reformulate the speech production task into predicting coarse and fine tokens from semantic tokens. Such formulation allows us to use a state-of-art generative model - an autoregressive transformer decoder. The very same model is used in ChatGPT. A lot of data is needed to train this beast: billions of tokens or thousands of hours of speech. This magnitude is only possible in a multi-speaker scenario, which requires to condition a generative model on speaker identity. It is done via “prompting” (natural language processing parallels intensify), where prompt - is an utterance of a speaker predecessing the current one. The prompt carries information about speaker identity, recording conditions, and even some high-level prosody aspects, but not the actual content. Fine tokens just refine the acoustic information from coarse tokens and don’t need as powerful modeling. The transformer encoder (i.e. parallel architecture) is used for fine tokens prediction to speed things up.
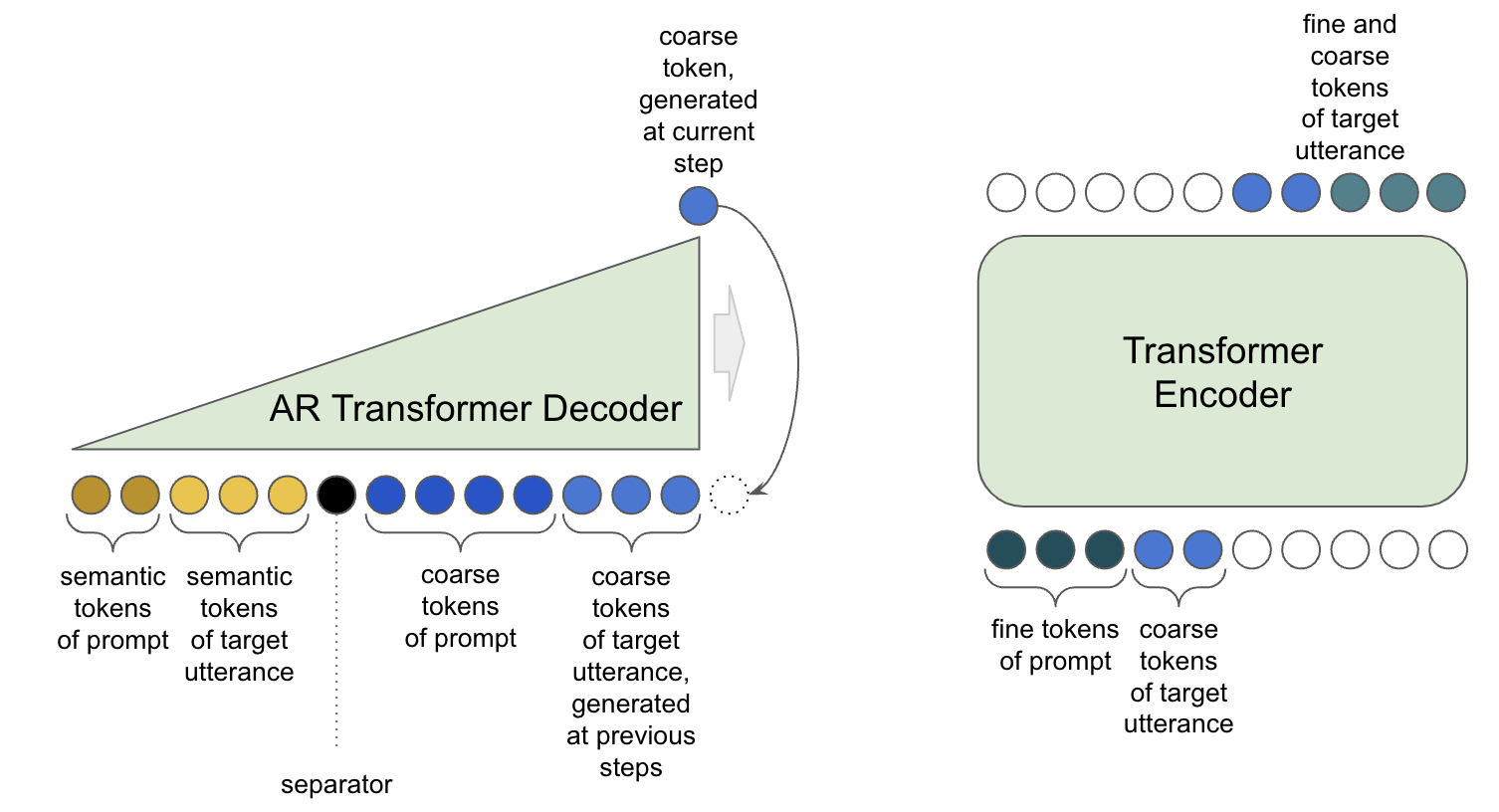
Coarse and fine tokens have multiple levels. To plug them into the models, token sequences are simply flattened.
Neural Frontend
Semantic tokens are extracted from the audio. For a text-to-speech task, they need to be predicted from the input text. It is done with yet another autoregressive transformer decoder. This task also requires a powerful generative model since it contributes to the resulting intonation. Converting text to semantic tokens is a sequence-to-sequence task, where correspondence is defined by durations of sounds and overall speech pace.
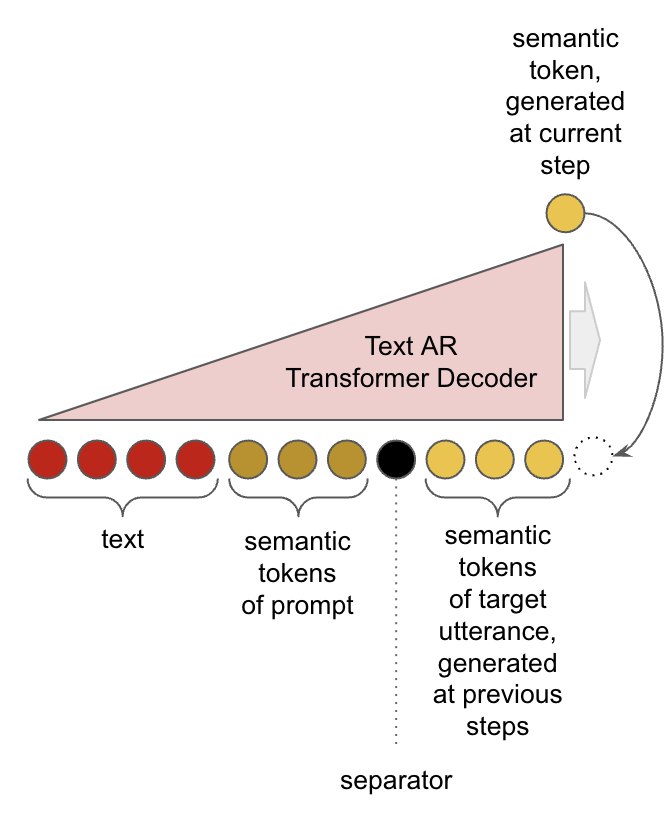
A sufficiently sizeable neural frontend has no problems generating semantic tokens for inputs in multiple languages or consistently annotated paralinguistics (laughs, breaths, gasps, etc.).
Performance
Generating speech with BARK is not fast. Let’s have a look into which components are the most demanding. Measurements are done on GPU, averaging inference time for multiple utterances of roughly 10 seconds each.
| Model | Function | Parameters | Average Inference time, s |
|---|---|---|---|
| HuBERT | audio → semantic tokens | 95M | 0.035 |
| Encodec Decoder | coarse/fine tokens → audio | 15M | 0.025 |
| Text AR Transformer Decoder | text → semantic tokens | 446M | 11 |
| AR Transformer Decoder | semantic tokens → coarse tokens | 328M | 45 |
| Transformer Encoder | coarse tokens → fine tokens | 319M | 0.37 |
Flattening coarse/fine tokens requires AR Transformer Decoder to work on a very long context. This makes it the slowest component of the whole pipeline by far.
Speeding things up
It’s not the first time slow autoregressive modeling has crossed out real-time speech generation. An autoregressive version of WaveNet[7] also puzzled the community back in the day with outstanding quality at the cost of extremely slow inference. But things got faster both with inference optimizations and modeling advances. The same applies in this case. For example, NaturalSpeech 2[8] proposes employing a parallel diffusion model instead of an autoregressive transformer decoder as a possible mitigation. We will have a brief look into possible inference optimizations.
RWKV
The quadratic complexity of attention fuels interest in so-called attention-free architectures. RWKV - is a parallelizable RNN with a performance of a classical transformer and linear complexity with respect to context length. Here is some code samples allowing to drag-race a dummy RWKV model and estimate expected gains. Creating a dummy model of 350M parameters (from within RWKV-v4):
from src.model import GPT, GPTConfig
import torch
model = GPT(GPTConfig(12096, 1024, model_type="RVKW", n_layer=24, n_embd=1024))
device = torch.device("cuda")
model.to(device)
torch.save(model.state_dict(), "rwkv_gpt2_medium.pth")
Run generation with a dummy model using rwkv from pip:
import time
import os
os.environ['RWKV_JIT_ON'] = '1'
os.environ["RWKV_CUDA_ON"] = '1'
from rwkv.model import RWKV
model = RWKV(model='rwkv_gpt2_medium.pth', strategy='cuda fp16')
state = None
# warm up
for i in range(100):
_, state = model.forward([100], state)
# measure generation of 1k tokens
state = None
start = time.time()
for _ in range(1000):
_, state = model.forward([100], state)
print(time.time() - start)
It takes ~12 seconds which is already a valuable improvement. It will become even more prominent with longer contexts and bigger models.
Faster Transformer
Faster Transformer is a library by NVIDIA which implements heavily optimized inference of Large Language Models. It runs in a dedicated docker container with custom CUDA kernels for particular models. Here is a small snippet of code to check out the performance on 350M GPT model:
# pulling container and building FT for you GPU
docker pull nvcr.io/nvidia/pytorch:22.09-py3
nvidia-docker run -ti --shm-size 5g --rm nvcr.io/nvidia/pytorch:22.09-py3 bash
git clone https://github.com/NVIDIA/FasterTransformer.git
mkdir -p FasterTransformer/build
cd FasterTransformer/build
git submodule init && git submodule update
# from https://github.com/NVIDIA/FasterTransformer/issues/90 for RTX3090
cmake -DSM=86 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON ..
make -j12
# pulling 350M GPT model
pip install -r ../examples/pytorch/gpt/requirement.txt
git clone https://huggingface.co/gpt2-medium
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
cd gpt2-medium && git lfs pull && cd ..
python ../examples/pytorch/gpt/utils/huggingface_gpt_convert.py -i gpt2-medium/ \
-o ../models/huggingface-models/c-model/gpt2-medium -i_g 1
echo "hello world" > context.txt
# run generation on a GPU for 1k tokens
time CUDA_VISIBLE_DEVICES=1 python ../examples/pytorch/gpt/multi_gpu_gpt_example.py \
--ckpt_path ../models/huggingface-models/c-model/gpt2-medium/1-gpu/ \
--time --inference_data_type fp16 --tensor_para_size 1 --pipeline_para_size 1 \
--beam_width 1 --top_k 1 --top_p 0 --temperature 1.0 --return_cum_log_probs 0 \
--output_len 1000 --vocab_file gpt2-medium/vocab.json --merges_file gpt2-medium/merges.txt \
--max_batch_size 1 --min_length 1000 --lib_path lib/libth_transformer.so \
--sample_input_file context.txt
It takes only 1.5 seconds, a mind-blowing speed up compared to the original performance.
References
[1] Hierarchical Text-Conditional Image Generation with CLIP Latents
[2] AudioLM: a Language Modeling Approach to Audio Generation
[3] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
[4] Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
[5] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
[6] High Fidelity Neural Audio Compression
[7] WaveNet: A Generative Model for Raw Audio
[8] NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers