Tracing mHuBERT
Clustering of self-supervised embeddings is commonly used as “semantic” tokens in audio generation. Typically wav2vec 2.0 or HuBERT outputs are used. A 95M-params multilingual HuBERT model (147 languages) was released recently. Despite its modest size, the model is competetive on the SUPERB leaderboard. This makes it a string candidate for use as a semantic tokens extractor in multilingual speech generation experiments.
Tracing
Converting model into Torch JIT file allows to run inference with minimal dependencies (just PyTorch) or deployment on inference servers (e.g. Triton). In this tracing, we integrate the clustering step into the Torch module, eliminating the need to carry around custom clustering code.
Unfortunately, the FAISS index for clustering step is only available for model after the second iteration. As a result, the traced model is slightly less capable.
The traced model is available at balacoon/mhubert-147. The full notebook used for tracing and testing can be found here.
Many thanks to @dathudeptrai for posting a snippet on discrete tokens extraction.
Notes
Here are some notes and practical findings from the mHuBERT model tracing. Please drop a message if any of these are incorrect or incomplete.
- The attention mask is ignored by mHuBERT. As a result, during batched inference, you can get different discrete codes depending on the padding:
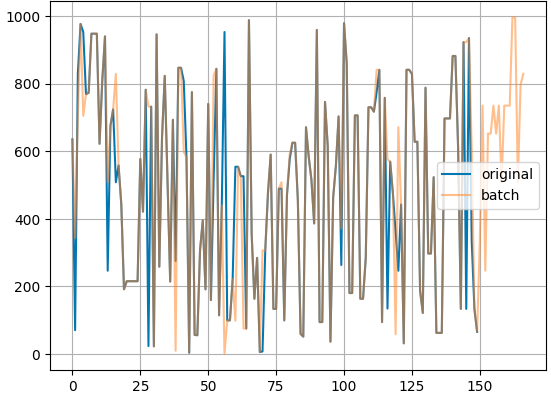
- mHuBERT applies mean/std normalization to input audio.
faisshas a lot of clustering methods implemented. Fortunately a linear transformation was used for clustering in mHuBERT, allowing it to be extracted into a transformation matrix. SeeTorchFaissin the notebook for details.