Super-resolution for TTS data
Zero-shot speech generation requires massive amounts of data. Large-scale speech datasets however are commonly collected for ASR and therefore sampled at 16khz. LibriTTS-R[1] work suggests that audio enhancement and super-resolution methods can be beneficial for TTS data processing. This blog compares a few open-source upsampling methods, aiming a usecase of preparing a TTS dataset (24kHz) from an ASR one (16kHz).
Methods
We compare the following methods:
- SoX - vanilla upsampling via interpolation, the higher frequencies are not restored.
- Resemble Enhance - diffusion-based denoising / enhancement / upsampling.
- AudioSR - diffusion-based audio super resolution.
- AP-BWE - GAN-based bandwidth extension in spectral domain.
Processing speed per file on a single RTX 3090:
| Method | Resemble Enhance | AudioSR | AP-BWE |
|---|---|---|---|
| Processing speed per file, sec | 8.0 | 5.0 | 0.035 |
We measure intelligibility, audio quality and speaker similarity of the processed audio on two datasets: VCTK[2] and DAPS[3]. First represents clean audio that simply lacks higher frequencies. Second - is a more challenging usecase of speech recorded on consumer microphones with background noise present. We use ECAPA[4] speaker encoder by Speechbrain to extract speaker representation and measure speaker similarity. We run speech recognition with Conformer-Transducer ASR model by NVIDIA to evaluate intelligibility in terms of Character Error Rate. Finally, we use a pre-trained Mean Opinion Score estimator UTMOS[5] to access the naturalness. Keep in mind that all the metrics are computed on 16khz audio, so they are mainly tracking if upsampling introduces any changes to the information that is already there.
VCTK testset
A 2k subset is sampled.
| Method | Naturalness(MOS↑) | Intelligibility(CER, %↓) | Similarity(inverted cosine distance↓) |
|---|---|---|---|
| original audio | 4.078 | 0.178 | 0 |
| SoX | 4.075 | 0.178 | 0.002 |
| Resemble Enhance | 3.86 | 0.18 | 0.079 |
| AudioSR | 4.05 | 0.178 | 0.039 |
| AP-BWE | 4.06 | 0.178 | 0.042 |
Example of the upsampling in spectral domain:
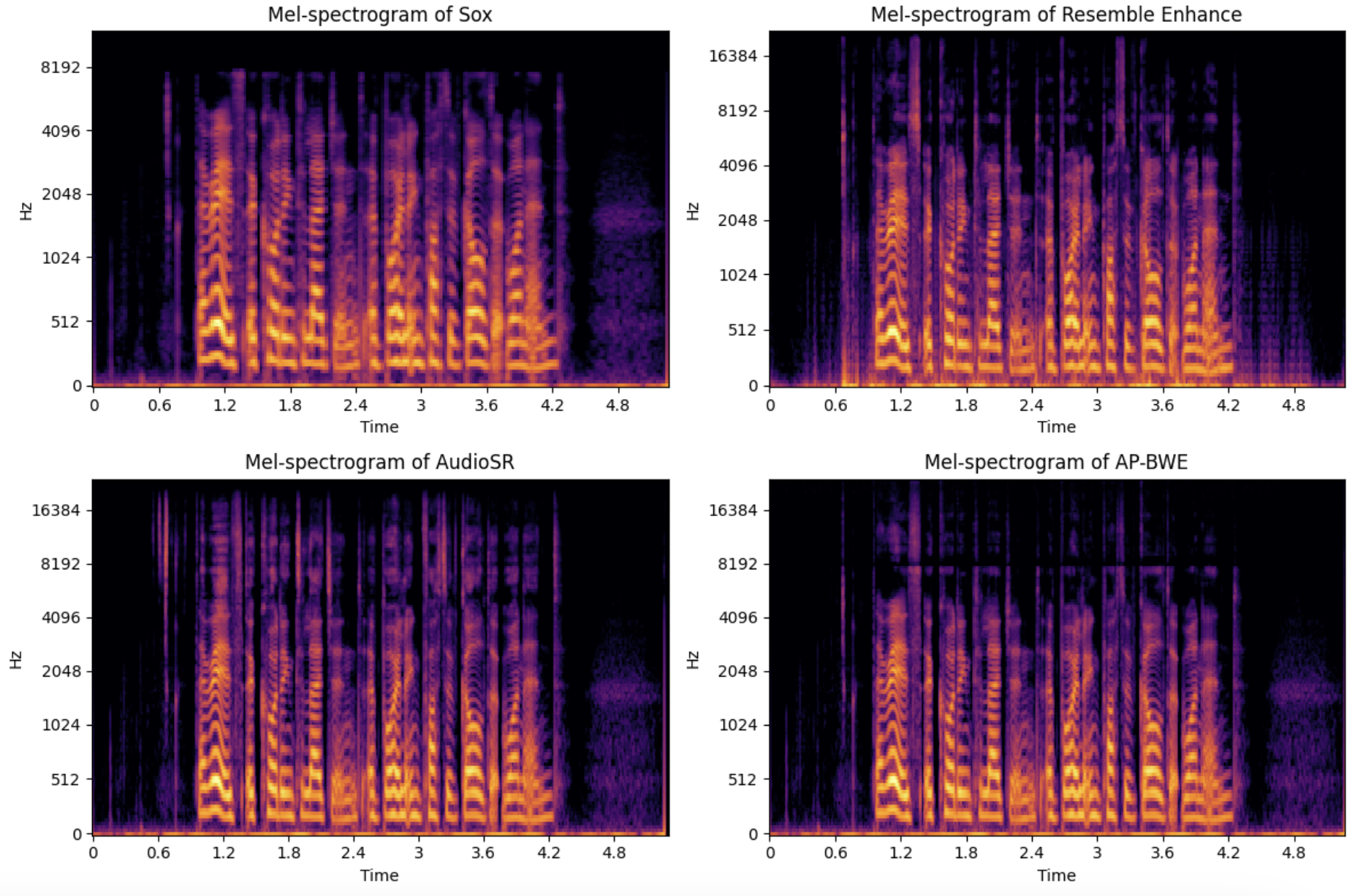
Audio samples:
DAPS testset
Dataset is segmented into sentence-level, a 2k subset is sampled.
| Model | Naturalness(MOS↑) | Intelligibility(CER, %↓) | Similarity(inverted cosine distance↓) |
|---|---|---|---|
| original audio | 2.48 | 2.75 | 0 |
| SoX | 2.48 | 2.748 | 0.008 |
| Resemble Enhance | 3.32 | 12.98 | 0.43 |
| AudioSR | 2.45 | 3.15 | 0.07 |
| AP-BWE | 2.456 | 2.73 | 0.007 |
Example of the upsampling in spectral domain:
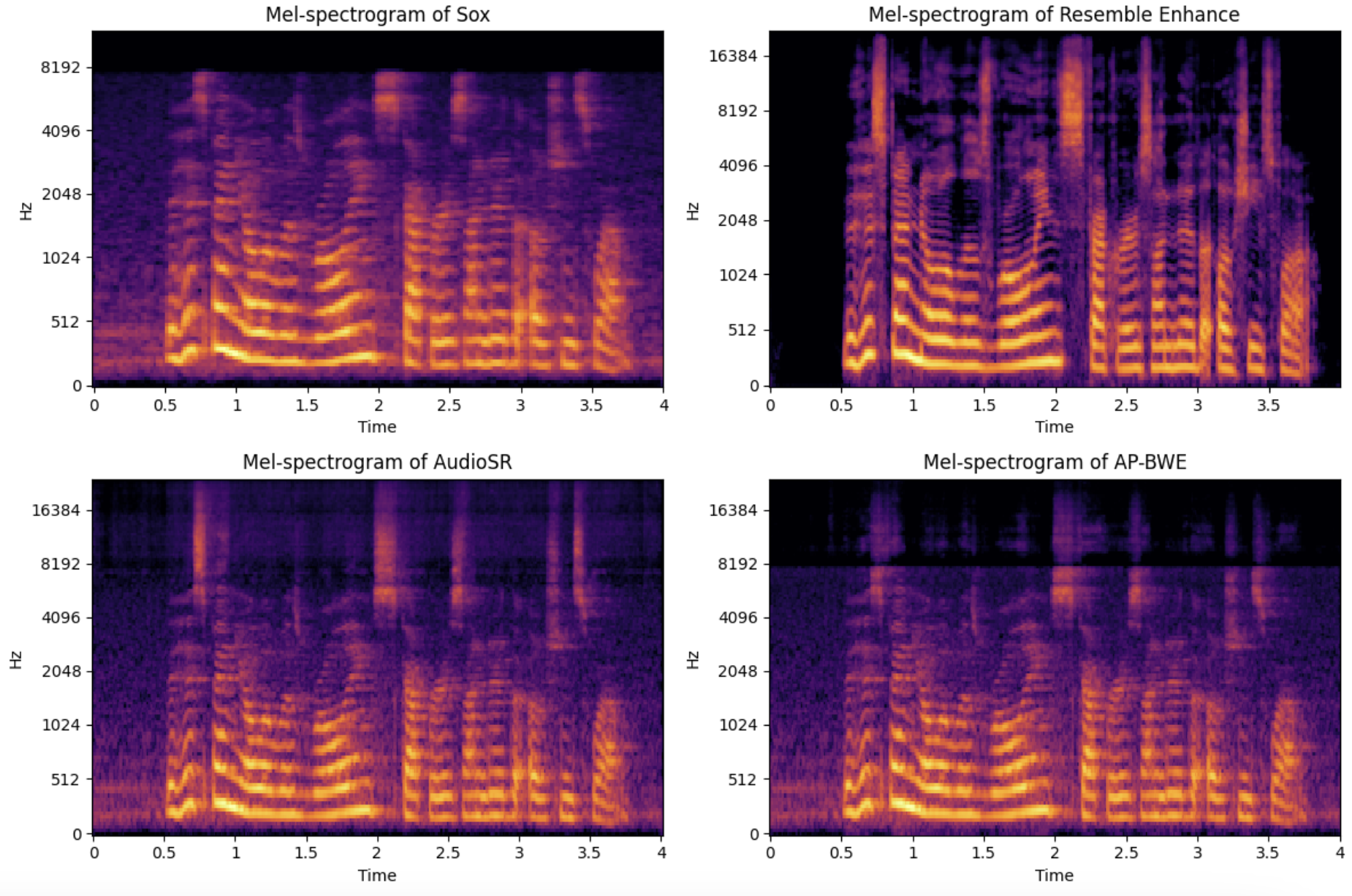
Audio samples:
Conclusions
Resemble-Enhance strives to also perform denoising and enhancement.
It corrupts the noisy audio files substantially which is reflected in greatly degraded intelligibility.
Both AudioSR and AP-BWE are very gentle to existing information and do not change the metrics.
Former adds more details and combines with existing high-freq information more smoothly.
Latter is however almost 150x faster. Our pick is AudioSR if the amount of data is managable, otherwise AP-BWE.
References
[1] LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
[2] CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit
[3] Device and Produced Speech (DAPS) Dataset
[4] ECAPA-TDNN Embeddings for Speaker Diarization
[5] UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022